


Data Lake Ingestion: from days to seconds

Today, we’ll discuss data ingestion into Data Lake tables. There are several key approaches to ingestion, each offering different latency - from days to seconds - depending on the trade-offs you choose.
Data ingestion has evolved alongside Big Data technologies. You might find my previous post on the history of Big Data useful, as I will reference it a few times in the text below.

What is Data Ingestion?
There are various approaches to data ingestion in the industry. However, most of the time, when we talk about ingestion, we’re referring to the ingestion of operational data from the service layer. In simple terms, when your business operates, it generates information based on user activity and business operations. Examples are product views, purchases, transfers, clicks, and more. This data can also include fleet health, changes in stock levels, consumption rates, and similar metrics.

Data typically arrives in the Data Lake through two main methods:
Event Sourcing. Data is emitted directly by the service as events.
Change Data Capture (CDC). Data is captured as changes from a transactional store.
Regardless of the method, the data ultimately lands in various Data Lake tables, which then serve as foundational sources for subsequent data analysis.
Now, let’s explore the different ways data can be ingested and added to a table.
1. Insert overwrite into a table partition
Key idea: full rewrite.
Freshness: hours to days.
This is the oldest classical method of ingesting data into a table. Long ago, when Hive was the most popular query engine, there were only two ways to insert new records into a Hive table:
“INSERT INTO <table> PARTITION (…)”. This command appends the given data to a specified partition.
“INSERT OVERWRITE <table> PARTITION (…)”. This command overwrites a specified partition with the given data.
Despite the appeal of the first approach, where batches of records can be ingested into a partition, it was not widely used. The main reason is that this operation was neither atomic nor idempotent. As a result, if the operation failed for any reason, the table could be left in an inconsistent state. The fact that an operation can be partially completed (because it’s not atomic) and cannot be repeated reliably (because it’s not idempotent) complicates the recovery process.
Consequently, the second approach, which involves overwriting a partition, became more widely used. For both ingestion paths in the above diagram, changes would typically be accumulated over an hour, and once the hour was complete, a partition would be added. In the case of the second ingestion path, operational storage could also be fully dumped periodically, for example, daily, into the corresponding partition.

Note that with this approach, the latency of data appearing in a table is tied to the granularity of the partition. Common choices are daily and hourly partitions. If your partition is created on an hourly basis, then, in the most straightforward scenario, you won’t see the data until after the hour has passed, even if portions of the data are available earlier.
While it is possible to write partial data and rewrite a partition multiple times, doing so results in higher computational and I/O costs. Additionally, any queries in progress at the time of the update would likely fail.
Despite its limitations, this older approach remains computationally and cost-efficient. It is still used in the industry, particularly in scenarios involving large volumes of data where real-time freshness is not a strict requirement.
2. Table Formats and CDC
Key idea: incremental load using Iceberg, Hudi, Delta formats.
Freshness: minutes to multiple times an hour.
Table formats such as Iceberg, Hudi, and Delta have introduced significant flexibility into Data Lakes. In particular, these formats make it possible to efficiently and atomically add new records to an existing table. They also eliminate the need for strict hourly or daily partitions, allowing for the ingestion of new batches of data as they arrive, without waiting for an hour or a day to pass.
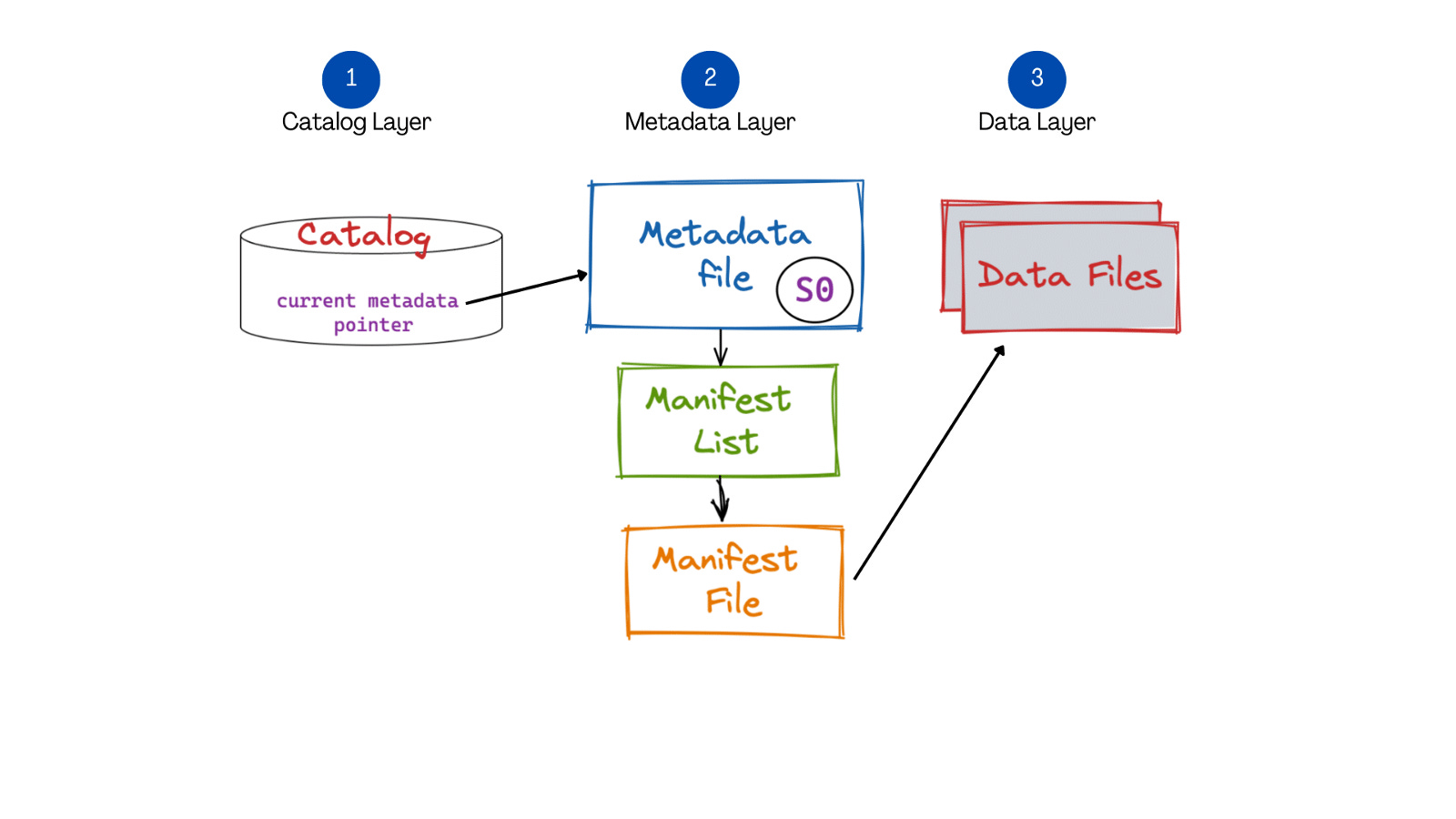
Ingesting append-only data has become much more straightforward. You can now wait until a sufficiently large batch of records is accumulated, then write it in a given format, such as to an Iceberg table, as incremental data. Iceberg table compaction will then handle merging smaller files and organizing the table for more efficient queries. While appending data is feasible, appending individual records or small batches is not efficient; thus, some delay is still necessary for optimal usage.
What about ingesting updatable data? The second ingestion path from the previous diagram can be done using Change Data Capture (CDC). With CDC, you first take a full snapshot or dump of the data. Future changes are captured via a stream of updates, where each insert, update, or delete is recorded as its own action. These changes are then applied in order to the snapshot data to produce the latest table state. Compared to periodic full dumps, this approach is particularly efficient for large tables with relatively few periodic modifications.

However, there are still a couple of challenges with merging data for updatable tables.
To update or delete existing records, table formats need to rewrite the corresponding data files. This copy-on-write (COW) operation, used by formats like Iceberg, can be relatively costly for frequently updated tables.
Copy-on-write can be deferred if a format supports adding incremental changes and merging them during read. However, merging base and incremental updates on the fly, as seen with merge-on-read (MOR) approaches like those used by Hudi, increases the cost of read queries.
To make ingestion less expensive, one can delay the merge operation. However, delaying the merge results in less fresh data. In practice, a balance is struck between rewrite cost, query cost, and data freshness by choosing an appropriate merge frequency.
3. LSM-based
Key idea: LSM-based engines for OLAP databases.
Freshness: seconds to minutes.
For near-real-time ingestion, especially with updatable datasets that require merging, an LSM-based solution is ideal. This approach allows data to be ingested in the order of seconds and queried efficiently afterwards. However, the implementation is significantly more complex and can be costly to run. This approach is more commonly used in specialized OLAP solutions. A notable example is the ClickHouse OLAP database with its MergeTree engine.

The Log-Structured Merge-Tree (LSM tree) is a data structure designed for efficient primary key indexing under high write volumes. LSM was popularized by NoSQL OLTP databases such as HBase and Cassandra, which use it to organize their data.
With some modifications, the LSM approach can also be applied to OLAP systems. In this context, you don't need an in-memory memtable; instead, you can allow for a delay before data is written to sorted string table (SST) files in batches. Periodic compaction merges smaller SST files into larger ones, making querying more efficient by reducing the number of files that need to be accessed to retrieve the final value for a given key.